초실감 메타버스를 위한 궁극의 3D 오디오 기술: 사운드 트레이싱 (Sound tracing)
세종대학교 컴퓨터공학과 박우찬
1. 서론
최근 메타버스(Metaverse)라는 용어가 산업계는 물론이고 학계에서도 주요하게 거론되는 키워드이다. 메타버스는 가상 혹은 초월을 의미하는 ‘메타’(meta)와 우주를 의미하는 ‘유니버스’(universe)를 합성한 신조어이다. 즉, 현실을 디지털 기반의 가상 세계로 확장해 가상공간에서 모든 활동을 할 수 있는 시스템을 의미한다. 실제로 메타버스의 개념은 단순한 이론적인 존재를 넘어, 현재 다양한 플랫폼과 서비스에서 구현되고 있으며, 그 활용 사례는 계속해서 확장되고 있다.
이러한 메타버스를 주도하고 있는 주체가 바로 IT 기업들이다. 많은 기업이 메타버스의 무한한 잠재력을 인지하며, 이를 중심으로 연구와 개발에 집중하고 있다. 특히 사용자의 몰입도와 현실감을 극대화하는 것이 주요 연구 주제로 부상하고 있다. 단순한 시각적 연구를 넘어서 청각적 연구도 큰 비중을 차지하게 되었는데, 이는 현존하는 오디오 기술의 한계를 인식하기 때문이다.

[그림 1] 애플의 Vision Pro (왼쪽)과 메타의 Meta Quest3 (오른쪽)
기존의 오디오 기술은 메타버스에서 원하는 수준의 몰입도와 현실감을 제공하기에는 한계가 있다. 이는 사용자 주위에 다양한 환경과 물리적인 특성들을 반영하기 어려워, 사용자들에게 초실감 오디오를 제공하는 데 어려움이 있다. 이러한 문제점을 극복하기 위해 많은 IT 기업이 초실감 오디오를 위한 연구개발을 진행 중이며 이에 대한 중요성을 강조하고 있다.
특히, 최근 애플은 메타버스와 유사한 개념인 공간 컴퓨팅(spatial computing)을 위한 HMD(Head Mounted Display) 기기인 Vision Pro를 공개하였고 자사 제품에서 제공되는 새로운 오디오 솔루션인 오디오 레이트레이싱(audio raytracing)을 지원한다고 발표하였다. 메타도 최근 혼합현실(Mixed Reality)을 위한 HMD로서 Meta Quest3를 발표하였고 해당 제품 또한 초실감 오디오를 강조하였다[1, 2].
이처럼 메타버스의 성공은 단순히 시각적인 경험을 넘어서, 청각적인 경험 또한 중요한 부분을 차지한다. 현실 세계의 모든 물리적인 특성과 상호작용을 디지털 환경에서 재현하기 위해서는 사운드 기술의 혁신이 필요하다. 최신의 IT 기기들이 초실감 오디오 기술을 강조하는 것 역시 이러한 트렌드의 반영이다. 본 기사에서는 오디오 기술의 동향과 최신 오디오 기술인 Geometric Acoustic (GA) 기반 사운드 트레이싱을 살펴보고, 본 연구팀에서 개발한 저전력/고성능을 위한 사운드 트레이싱 하드웨어를 소개한다.
2. 오디오 기술 동향
현재 사용되고 있는 오디오 기술은 크게 3가지로 나눠진다: 멀티채널 오디오 (Multi-channel audio), HRTF (Head-Related Transfer Function), 사운드 렌더링 (Sound Rendering).
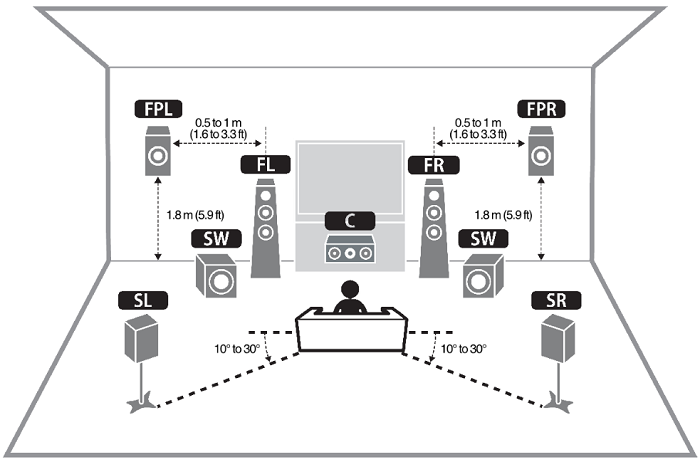
[그림 2] 7.2 멀티채널 오디오 예시 (front left (FL), front right (FR), center (C), surround left (SL), surround right (SR), front presence L (FPL), front presence right (FPR), subwoofer (SW) * 2) [3]
멀티채널 오디오는 다양한 스피커들을 활용하여 청취자 주변에 입체적인 소리를 제공하는 기술이다. 5.1, 7.1 혹은 그 이상의 채널을 활용하여, 청취자는 실제 환경과 같은 소리의 방향성을 경험할 수 있다 ([그림 2] 참조). 영화관, 홈시어터 등에서 이 기술을 활용하여 청취자에게 깊은 몰입감을 제공한다. Dolby나 Auro3D와 같은 오디오 전문 회사들이 이러한 방식을 채택하여서 사용자들에게 제공하고 있다.
하지만 메타버스 환경에서는 이 방식이 몇 가지 한계를 가진다. 첫째, 멀티채널 사운드를 경험하려면 특정 형식을 지원하는 스피커를 별도로 구매해야 하고, 그 설치를 위한 공간도 필요하다. 둘째, 스피커의 위치가 정해져 있어 사용자의 위치나 방향이 바뀜에 따라 소리를 다시 조절해야 한다.
HRTF는 음원(sound source)의 방향에 따른 소리의 진폭(amplitude)을 정확하게 재현하기 위해 사용되는 기술이다. 인간의 귀와 머리의 형태는 소리가 어떻게 들려오는지에 큰 영향을 미치는데, HRTF는 이런 특징을 이용한다. 이를 구현하기 위해서는 음원의 방향에 따른 소리의 감쇄 값(attenuation) 테이블이 필요하다. 이는 실제 무향실에서 스피커와 사람의 머리와 귀의 형태를 모방한 마이크를 사용하여 다양한 방향에서의 주파수 대역별 감쇄 값을 측정하여 생성한다.
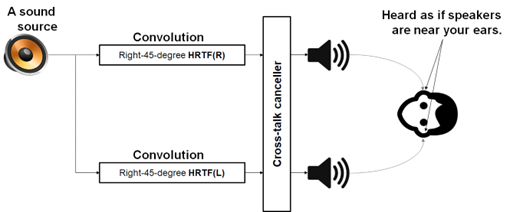
[그림 3] HRTF 처리 방식의 예시
[그림 3]은 HRTF 처리 방식을 보여주고 있다. 만약 음원으로부터 귀까지의 방향이 정해지면, 방향에 따라서 주파수 대역별 감쇄 테이블로부터 감쇄 값을 가져온다. 그 후 음원 데이터와 감쇄 값의 콘볼루션 연산을 통해 최종 오디오를 생성한다. 해당 방식은 방향에 따른 감쇄를 주파수 대역별로 가지고 있기 때문에 사람들에게 높은 오디오 퀄리티를 제공 해줄 수 있다.
그러나, 사람마다 머리와 귀의 크기와 형태가 전부 상이하기 때문에 일관된 경험이 어렵고, 음원의 개수가 많아졌을 때 계산 복잡도가 올라가 애플리케이션 성능에 문제가 생긴다. 게다가, 방향에 특화된 방식이기 때문에 실제 물리적인 소리 효과를 반영하지 못한다.
마지막으로, 사운드 렌더링은 음원을 생성하는 음원 합성 단계, 소리의 파형을 모델링하는 사운드 전파 단계, 최종 오디오 시그널을 생성하는 사운드 생성 단계를 거쳐서 청취자 주위에 물리적인 소리 효과들을 계산하여 현실적인 소리를 만들어 내는 기술이다. 즉, 청취자, 음원, 주변 환경(재질, 차폐, 방 크기 등)들과의 상호작용을 전부 고려하여서 현실과 같은 물리적인 소리가 만들어진다.
이 중 핵심 단계는 소리의 파형을 모델링하여서 청취자 주위에 물리적인 환경을 반영하게 해주는 사운드 전파이다. 이는 일반적으로 wave 기반 방식과 geometric acoustic (GA) 기반 방식으로 나뉜다. Wave 기반 방식은 2차 편미분 방정식(second-order partial differential equation)으로 이루어진 파동방정식을 풀면서 실제 소리 파형을 그대로 구현하는 방식이다. 이는 매우 정확하게 현실과 같은 소리가 가능하지만 엄청난 컴퓨팅 비용을 필요로 한다. 이러한 이유로 실시간(real-time rates) 처리를 필요로 하는 메타버스와 같은 콘텐츠에서는 사용이 불가하다.
반면에 GA 방식은 소리의 파동을 직접적으로 모델링하는 대신 ray, beam, frustum 등을 이용하여서 음원, 청취자, 그리고 씬의 기하학적 정보 (geometry information of scene) 사이에 유효한 경로(path)들을 찾는 것이다. 해당 경로들은 소리를 생성하기 위한 여러 매개변수(parameters)를 만드는데 기여한다. 예를 들어, 소리의 방향, 소리의 속도, 소리의 딜레이, 차폐 여부, 주파수 밴드에 따른 감쇄 등이 있고 이들은 Impulse Response (IR)이라는 형태로 압축되어 저장된다. 이와 같은 정보들은 최종적으로 스피커나 이어폰과 같은 end-point device에서 출력될 소리를 형성하는 데 사용된다.
GA 방식은 wave 방식보다 상대적으로 대략적인(approximately) 방식이지만 더 좋은 성능을 제공하여서 메타버스와 같은 실시간 애플리케이션에 적합하다. 본 연구팀은 레이 트레이싱(ray tracing)을 이용한 GA 기반 사운드 전파 방식을 오랫동안 연구해 왔으며, 이를 사운드 트레이싱(sound + ray tracing = sound tracing)이라고 명명했다. 이하 본문에서는 사운드 전파를 사운드 트레이싱(혹은 sound tracing)이라고 표기한다.
3. Ray를 이용한 사운드 트레이싱
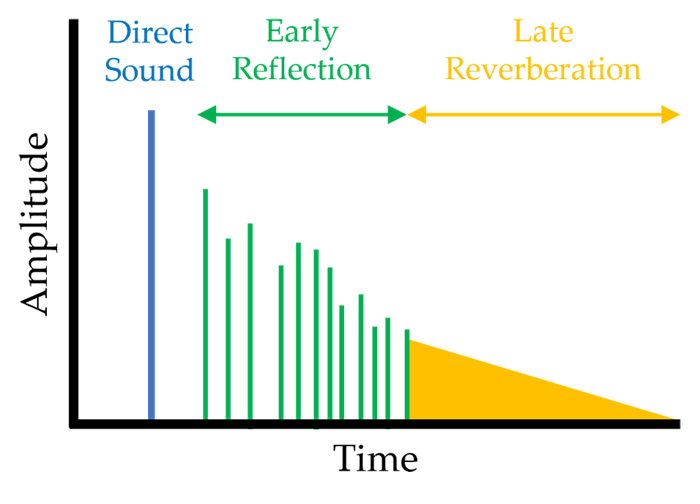
[그림 4] 시간에 따른 다양한 소리 효과들의 amplitude (direct sound, ER, LR)
사운드 트레이싱은 ray를 이용해 다양한 소리 효과를 만들 수 있다. [그림4]는 시간에 따라서 소리 효과들(direct sound, early reflection (ER), late reverberation (LR))의 amplitude 특성을 보여준다. Direct sound는 음원으로부터 청취자까지 직접 오는 소리이며 음원과 청취자 사이에 방향과 거리에 따른 높은 기여도를 가지고 다른 효과들에 비해서 상대적으로 amplitude도 매우 크다.
ER은 직접음이 도착한 이후에 들어오는 반사음(echo)이며, 일반적으로 직접음 ~ 60ms의 사이의 딜레이를 충족하는 반사음들로 ER이 정의된다. 이는 오브젝트들과의 반사로 인해 상대적으로 작은 amplitude를 가지지만 direct sound의 amplitude를 보강할 수 있고 소리를 좀 더 명료해지게 만든다.
마지막으로 LR은 잔향음 (2차 반사음)으로 초기반사음 이후에 들어오는 반사음들을 의미한다. 현실에서 콘서트홀이나 연주회장 같은 곳에서 울림소리를 들을 수 있는데 이와 같은 소리가 바로 잔향음이다. 이는 소리를 더 풍부하게 만들어 주고 청취자에게 주변 공간의 크기, 재질, 반사율 등을 어느 정도 인지하게 만들 수 있다.
이와 같은 다양한 소리 효과들이 생성되어야만 현실과 유사한 소리를 생성해 낼 수 있는데, 이들은 ray를 이용한 사운드 트레이싱을 통해 실현할 수 있다. 이 방법은 레이 트레이싱과 매우 유사하다. 레이 트레이싱은 빛이 여러 방향으로 발사되어 다양한 객체와 상호작용하여, 최종적으로 우리 눈에 반사되어 오는 빛의 색상을 계산한다. 이와 마찬가지로 사운드 트레이싱은 음원으로부터 발사되는 ray(소리)가 여러 방향으로 퍼져나가고 주변 환경과 상호작용하게 되어 최종적으로 우리 귀로 들어오게 되는 소리를 찾는 것이다.
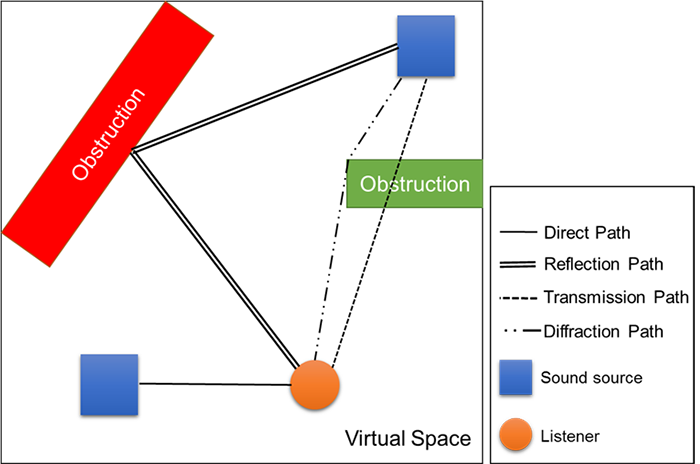
[그림 5] 사운드 트레이싱 path의 종류

[그림 6] 사운드 트레이싱 SW 모바일 데모
사운드 트레이싱의 처리 방식은 다음과 같다. 먼저 다수 개의 음원의 위치에서 ray를 슈팅하고 청취자 위치에서 ray를 슈팅한다. 슈팅 된 각각의 ray는 자신과 hit 된 primitive(예, triangle)를 찾고, hit 된 primitive에 대하여 반사, 투과, 회절에 해당하는 ray를 생성한다. 이와 같은 처리는 ray의 생성, 탐색, 충돌검사라고 명명한다. 이러한 과정이 재귀적(recursive)으로 수행되면서 사운드 트레이싱 path의 IR과 잔향의 IR를 만든다.
음원(혹은 청취자)에서 슈팅 된 ray가 청취자(혹은 음원)와 만나게 될 수 있으며, 만나게 되는 path를 사운드 트레이싱 path라고 한다. 이는 결국 음원(혹은 청취자) 위치에서 출발한 sound가 그림 5와 6과 같이 반사, 투과, 흡수, 회절 등을 거쳐서 청취자(혹은 음원)에 도착하는 유효한 path를 의미한다. 이러한 사운드 트레이싱 paths를 기반하여 IRs들이 계산된다.
사운드 트레이싱은 잔향을 생성하기 위한 모델로서 Eyring model[4]을 이용하는데, 이는 음원의 intensity가 얼마나 떨어져야 하고 얼마 동안 잔향이 생성되어야 하는지를 계산할 수 있다. Eyring model을 사용하기 위해선 필요한 몇 가지 매개변수들을 필요하며 대표적으로 공간의 넓이와 부피, 표면의 평균 흡수 계수 등이 있다. 이러한 매개변수들을 구하기 위해 음원과 청취자로부터 슈팅되어 hit 된 primitive들이 이용된다. 계산된 매개변수들은 IR로 압축되어 저장된다. 최종 오디오는 사운드 트레이싱 paths로 생성된 IRs과 잔향의 IRs을 이용하여서 생성되어 스피커나 헤드셋을 통해 출력된다.
사운드 트레이싱은 초실감 메타버스에 적합한 오디오 기술이지만 몇 가지 단점들이 있다. 첫째, 많은 컴퓨팅 자원을 필요로 한다. 이로 인해 다른 중요한 작업들(예, 그래픽 프로세싱)에게 영향을 미치면 애플리케이션 전반적으로 문제를 야기할 수 있다. 둘째, 너무 많은 전력이 소비된다. 소비 전력이 크다면 모바일 같은 환경에선 쓰로틀링¹ (throttling) 현상이 생기고 이는 성능 저하로 직결된다. 마지막으로, 음원의 개수가 많아졌을 때 사운드 트레이싱의 컴퓨팅 복잡도가 올라가서 실시간 처리를 위한 성능(예, 30 FPS or 60 FPS)까지 나오지 않는다.
본 연구팀은 이러한 문제들을 해결하기 위해 사운드 트레이싱을 가속하기 위한 별도의 전용 하드웨어를 설계 및 구현하였다. 이를 통해 저전력/고성능을 달성했을 뿐만 아니라 fully dynamic scene²까지 지원하여서 메타버스 환경에서 안정적으로 고품질의 오디오 경험을 제공할 수 있다.
¹쓰로틀링(throttling): CPU나 GPU가 지나치게 과열되는 현상을 막기 위해 클록과 전압을 강제적으로 낮추거나 전원을 꺼서 발열을 줄이는 기능.
²다이나믹 씬(dynamic scene): 시간에 따라서 혹은 사용자의 상호작용에 반응하여 변환하는 객체들을 포함하는 환경.
4. 본 연구팀의 사운드 트레이싱 하드웨어
사운드 트레이싱 하드웨어는 ray tracing 하드웨어를 기반으로 한 기술이기 때문에 기술의 난이도가 매우 높으며, 전 세계적으로 개발된 사례가 없다. 본 연구팀은 20여 년간 레이 트레이싱 하드웨어에 대한 연구개발 노하우를 기반으로 사운드 트레이싱 하드웨어를 설계 및 구현하였다[6, 7].
[그림7]은 사운드 트레이싱 IP³가 구현되어 있는 Xilinx 보드, Host(예, PC, mobile device), 그리고 Xilinx 보드와 Host를 통신하기 위한 FMC 보드를 보여준다. 사운드 트레이싱 하드웨어는 호스트로부터 USB3.0을 통해 geometry data, 음원 데이터, 가속 구조체⁴ 정보 등을 받고 나서 하드웨어 시작 신호를 받으면 사운드 트레이싱 처리를 담당하는 sound tracing unit이 시작된다.
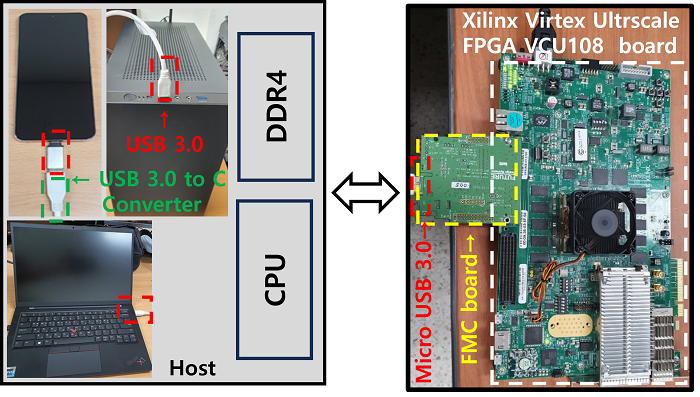
[그림 7] Sound tracing 하드웨어는 sound tracing IP가 들어가 있는 Xilinx Virtex Ultrascale과 호스트와 연결하기 위한 FMC 보드로 구성되어 있고 USB 3.0을 통해 호스트 데이터를 주고받음.
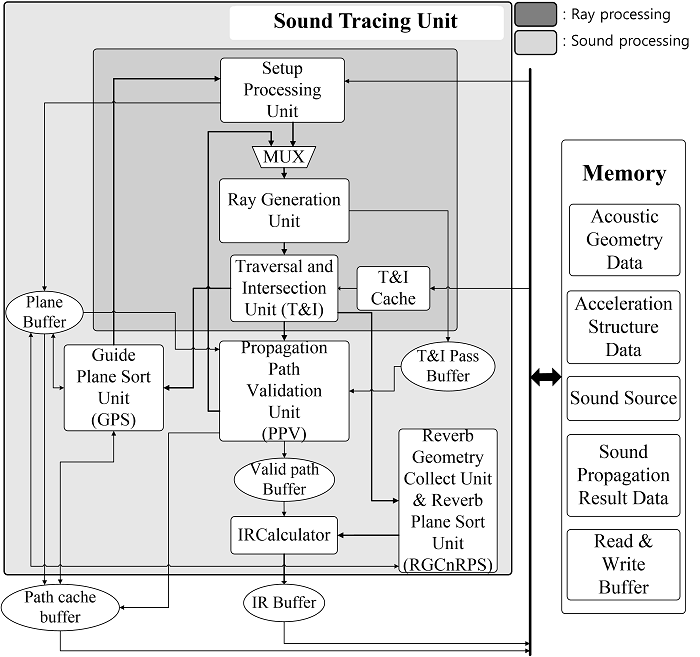
[그림 8] 본 연구팀이 설계한 sound tracing unit의 전체 아키텍처
[그림8]은 본 연구팀이 설계한 sound tracing unit의 전체 아키텍처를 보여준다. 이는 ray processing과 sound processing으로 나뉜다. Ray processing은 레이 트레이싱을 담당하는 units 들로 ray의 생성, 탐색, 교차 테스트 등을 담당한다. 반면에, sound processing은 소리를 생성할 수 있는 유효한 경로들을 찾는 units 들로 ray processing에 의해 찾아진 primitive들이 어떤 타입(반사, 회절 등)의 paths를 생성할 수 있는지, 유효한 경로들인지에 대한 검증, 찾아진 유효한 경로들에 대한 IRs 계산 등을 수행한다.
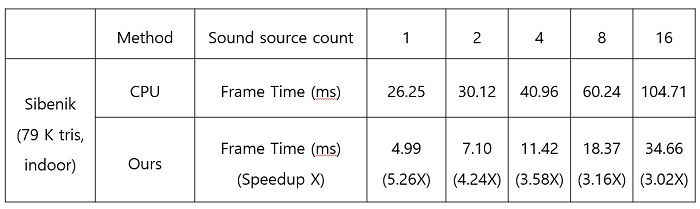
표1. CPU 방식과 사운드 트레이싱 하드웨어 음원 개수별 성능 비교
본 연구팀은 사운드 트레이싱 FPGA(140MHz)의 성능을 측정하기 위해 그래픽스 분야에서 많이 사용되는 Sibenik (79,000개 triangles, indoor) 씬에서 CPU (i9-10850k 3.6GHz) 가속 방식의 사운드 트레이싱과 비교하였다. 실험은 음원의 개수를 늘려가면서 사운드 트레이싱의 평균 frame time (처리 속도)을 측정하였다. 결과적으로 사운드 트레이싱 FPGA의 성능이 CPU 가속 방식보다 평균 3.85배 빠르게 처리되었다.
본 연구팀이 사운드 트레이싱 ASIC⁵의 성능을 알아보기 위해 PPA (performance, power, area) 지표를 이용하여 측정하였다. 이 지표는 ASIC의 성능, 전력, 면적을 평가하는 요소로서 반도체 설계 분야에서 널리 쓰이고 있다. 본 연구팀은 해당 지표를 측정하기 위해 8nm 설계 공정과 디자인 컴파일러 툴을 활용하였다. 결과적으로 사운드 트레이싱 ASIC의 PPA는 900MHz 성능, 50mW 전력, 0.31mm² 사이즈를 보여주었다. ASIC의 성능은 FPGA 성능보다 약 6.42배 높아지는 것이고, ASIC의 전력은 i9-10850k(125W)와 비교하면 많은 차이를 보이며, ASIC의 사이즈는 최근 모바일 AP의 사이즈가 100 mm²을 넘어가는 것을 감안하면 매우 작은 것을 알 수 있다[5]. 이러한 결과는 본 연구를 통해 개발된 사운드 트레이싱이 성능, 전력 소모, 크기 면에서 우수성을 검증하였으며 초실감 메타버스를 위한 실시간 3D 오디오를 실현이 충분하다는 것을 보여주었다.
³IP(Intellectual Property): 특정 기능을 수행하는 회로 설계와 관련된 지적 재산을 의미.
⁴가속구조체(Accleration Structure (AS)): 3D 공간을 효율적으로 분할하여 트리 형태로 저장하고, 이를 이용하여 ray와 객체들 간의 교차점을 효율적으로 찾게 도와줌.
⁵ASIC(Application-Specific Integrated Circuit): 특정 응용프로그램이나 기능을 위해 맞춤 설계된 직접 회로 (반도체).
5 결론
메타버스에 대한 전 세계적인 관심이 급증함에 따라, 사용자의 몰입도를 극대화하기 위한 연구와 개발 노력이 증가하고 있다. 특히, 청각적인 요소는 사용자 경험에 있어 중요한 역할을 차지하며, 사운드 렌더링은 이러한 몰입도를 높이는 데에 있어 핵심적인 기술로 부상하고 있다. 기존의 오디오 처리 방식들은 몰입도를 높이는 한계가 있지만 사운드 렌더링은 높은 몰입도와 현실감을 가진 오디오 경험을 제공한다. 그러나 해당 방식은 높은 계산 비용을 수반하여 이를 실시간으로 처리하기 어렵다.
본 연구팀은 이러한 문제를 해결하기 위해, 수십 년에 걸친 레이 트레이싱 하드웨어 개발 경험을 바탕으로 고성능 사운드 트레이싱 하드웨어를 설계 및 구현하였다. 이 하드웨어는 기존 CPU 방식보다 평균 3.85배 빠른 처리 속도를 보여주며, 성능, 전력 소모, 크기 면에서도 매우 우수하다. 특히, 사운드 트레이싱 ASIC의 성능은 FPGA보다 약 6.42배 높아, 초실감 메타버스 환경에서 실시간 오디오를 제공하는 데 충분하다. 이러한 성과를 바탕으로, 본 연구팀의 사운드 트레이싱 하드웨어는 초실감형 메타버스와 같은 고성능 오디오 처리가 필요한 애플리케이션에 적합한 솔루션을 제공할 수 있는 기반이 될 것이다. 연구팀의 노력과 혁신을 통해 더욱더 현실적이고 몰입감 있는 메타버스 환경이 가능하다.
참고문헌
[1] https://www.wepc.com/tips/apple-audio-ray-tracing-explained/
[2] https://about.fb.com/news/2023/09/meet-meta-quest-3-mixed-reality-headset/
[3] https://manual.yamaha.com/av/18/rxv685/en-US/448935819.html
[4] Carl F Eyring. 1930. Reverberation time in “dead” rooms. The Journal of the Acoustical Society of America 1, 2A (1930), 217–241.
[5] https://www.anandtech.com/show/16983/the-apple-a15-soc-performance-
review-faster-more-efficient/3
[6] Eunjae Kim, Sukwon Choi, Jiyoung Kim, Jae-ho Nah, Woonam Jung, Tae-hyeong Lee, Yeon-kug Moon, and Woo-chan Park, "An Architecture and Implementation of Real-Time Sound Propagation Hardware for Mobile Devices," SIGGRAPH ASIA, Accepted to appear.
[7] Eunjae Kim, Sukwon Choi, Cheong Ghil Kim, and Woo-Chan Park, "Multi-Threaded Sound Propagation Algorithm to Improve Performance on Mobile Devices," Sensors, Vol. 23, No. 2, p. 973. Jan 2023.