나노소자를 활용한 생물학적 신경망의 모사:미래 AI 기술을 위한 뉴로모픽 컴퓨팅
세종대학교 전자정보통신공학과 김성호
요 약
최근 인공지능 기술의 활용성 증가에 따라 인공지능이 보다 효율적으로 실행될 수 있는 컴퓨팅 기술 개선에 대한 필요성도 증가하고 있다. 뉴로모픽 컴퓨팅은 뇌의 기능적/구조적 특징을 모사하여 보다 에너지 효율적인 연산을 수행하는 것을 목표로 한다. 본고에서는 소자 수준에서 뉴로모픽 시스템 구현을 위한 현재의 연구 동향과 이슈들에 대해 살펴본다.
Ⅰ. 서 론
인공지능(AI)은 1940년대 영국의 수학자인 튜링(Turing)이 제안한 이래로 줄곧 컴퓨터공학의 한 분야로서 연구된, 생각보다 오래된 학문 분야이다[1]. 하지만 긴 연구 역사와는 달리 최근에 들어서야 본격적으로 AI가 이미지/음성 인식, 소셜 네트워크, 금융, 의료, 보안 등과 같은 여러 응용 분야에서 활용되기 시작하고 있다. 이러한 최근의 급격한 AI 발전 배경에는 활용 가능한 빅데이터(big data)의 증가와 더불어 역전파(back propagation)방식 기반의 인공신경망(Artificial Neural Network, ANN) 훈련을 위한 GPU(graphics processing unit)의 성능 개선이 크게 기여했기 때문이다. 쉽게 말하면, 학습에 활용할 데이터 양이 충분해짐과 동시에 학습 데이터를 처리할 수 있는 컴퓨팅 성능이 확보되면서 AI가 본격적으로 구현 가능해졌다는 뜻이다. 이를 조금 더 깊이 생각해보면, 흔히들 AI 기술은 컴퓨터공학의 분야로서 소프트웨어 개발이 핵심일 것이라 생각하기 쉽지만, 사실은 빅데이터를 처리할 수 있는 컴퓨팅 능력 역시 중요한 요소라는 것이다. 즉 AI의 지속적인 성능 개선을 위해서는 알고리즘/아키텍처 개발을 통해 소프트웨어적으로 효율성을 증가시키는 것도 중요하지만, 컴퓨팅 능력 향상을 위한 하드웨어적 개발이 반드시 뒷받침되어야 한다. 문제는 현재의 디지털 기반 컴퓨팅 시스템의 속도 및 에너지 효율은 이론적인 한계에 빠르게 도달하고 있다는 점이다[2].
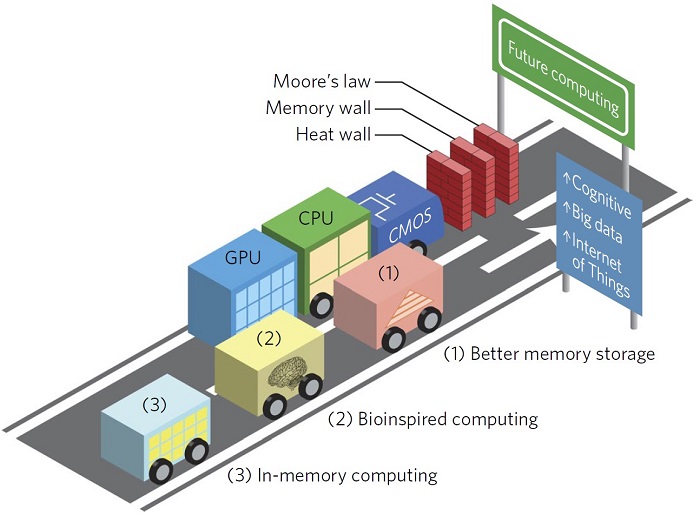
그림 1. 기존의 컴퓨팅 시스템이 직면한 무어의 법칙의 한계, 메모리 장벽, 열적 장벽 문제[2].
지난 60여년동안 디지털 컴퓨팅 시스템의 속도는 성공적으로 그리고 아주 비약적으로 발전해왔다. 그 배경에는 나노공정기술을 바탕으로 한 트랜지스터의 소형화(scaling-down)가 주된 역할을 해왔다. 트랜지스터가 작아질수록 동작속도는 점점 빨라졌으며, 칩(chip)에 들어갈 수 있는 트랜지스터의 수는 점점 늘어나 더욱더 빠른 연산이 가능한 메모리 또는 프로세서 구현이 가능해졌다. 하지만 문제는 예상치 못한 엉뚱한 곳에서 발생하고 있다. 현재의 컴퓨팅 시스템 성능 개선을 방해하는 가장 큰 장애물은 물리적으로 분리된 메모리와 프로세서 사이에 발생하는 빅데이터 이동의 병목현상이며, 이는 폰 노이만 병목현상(또는 메모리 장벽, 그림1)이라 불리고 있다. 한번 상상해보자. 운동회에서 두 사람이 발목을 묶고 뛰는 2인3각 경기에서 두 사람의 속도는 둘 중 더 느린 사람에 의해 결정된다. 컴퓨팅 시스템에서도 이와 마찬가지로 메모리와 프로세서가 서로 도와가며 연산을 수행하기 때문에 전체 연산 속도는 둘 중 느린 것에 의해 결정된다. 하지만 예전에는 메모리 또는 프로세서의 속도에 의해 전체 컴퓨팅 시스템의 속도가 결정된 반면, 현재에는 오히려 이 둘 사이의 느린 데이터 전송 속도가 발목을 잡고 있다. 메모리와 프로세서는 서로 분리된 칩 형태로 제작되기 때문에 (현재의 공정 기술로는 하나의 칩 안에 제작이 불가능하다), 물리적으로 떨어져 있을 수밖에 없고, 따라서 데이터 전송속도를 높이는 방법을 찾기가 현재로서는 요원하다. 결국 이러한 폰 노이만 병목현상은 메모리와 프로세서의 성능이 개선됨에도 불구하고 전체 컴퓨팅 시스템의 성능이 증가하지 못하는 주된 원인이 되고 있다. 따라서 현재의 AI 기술은 컴퓨터공학적 문제가 아니라 오히려 하드웨어적 한계에 발목이 잡혀 있으며, 이를 극복할 수 있는 새로운 개념의 컴퓨팅 기술이 미래의 AI기술을 위해 절실히 요구되고 있는 상황이다.
최근 들어 뇌로부터 영감을 얻어, 생물학적 신경망의 기능적/구조적 특징을 모사하여 아날로그적 또는 병렬적으로 연산을 수행하는 뉴로모픽(neuromorphic) 컴퓨팅 기술이 주목받고 있다. 이런 뉴로모픽 컴퓨팅은 최신 CPU/GPU에 비해서도 3000배 이상 빠른 속도로 딥러닝(deep learning) 연산을 수행할 수 있을 것으로 예상하고 있다[3]. 사실 이러한 뉴로모픽 컴퓨팅을 위한 하드웨어 개발 연구는 이미 1950년대부터 시작된 오래된 연구 분야이다[4]. CMOS 집적 회로를 사용하여 신경망의 역학과정을 모사하려는 연구가 주로 수행되어왔으며, 하드웨어적으로 모사한 인공적인 뉴런-시냅스 네트워크 (앞으로 하드웨어 ANN이라 지칭하겠음) 기반의 컴퓨팅 시스템을 뉴로모픽 시스템이라 지칭한다[5]. 최근의 가장 발전된 사례로는 4096 개의 코어(1코어=256개 뉴런+256개 시냅스)가 집적된 IBM 의 TrueNorth 칩[6], 128 개의 코어(1코어=1024 개 뉴런+4096개 시냅스)가 집적된 Intel 의 Loihi 칩[7]이 있다. 그러나 기존의 CMOS 기반 뉴로모픽 시스템은 미래의 AI 를 위한 하드웨어로서 궁극적인 해결책이 아닐 가능성이 높다[8]. 복잡한 회로 구조 때문에 칩 면적이 크며, 전력 소모가 여전히 많고, CMOS 스케일링(scaling) 속도가 점점 둔화되는 것이 문제이다. 따라서 이에 병행하여 나노소자를 활용한 하드웨어 ANN 구현 연구가 2000년대부터 진행되었다[9]. 다양한 메커니즘 기반의 비휘발성/휘발성 저항변화특성을 가진 나노소자는 생물학적 뉴런/시냅스의 역학과정을 쉽게 모사할 수 있었다. 또한 나노소자의 크로스바 어레이(crossbar array) 구조는 생물학적 신경망의 복잡한 병렬성을 쉽게 모사할 수 있었다(그림2). 따라서 CMOS 가 아닌 나노소자 기반의 하드웨어 ANN을 활용한 뉴로모픽 시스템에 대한 가능성은 나노소자기술의 발전에 힘입어 급격히 증가하였다.
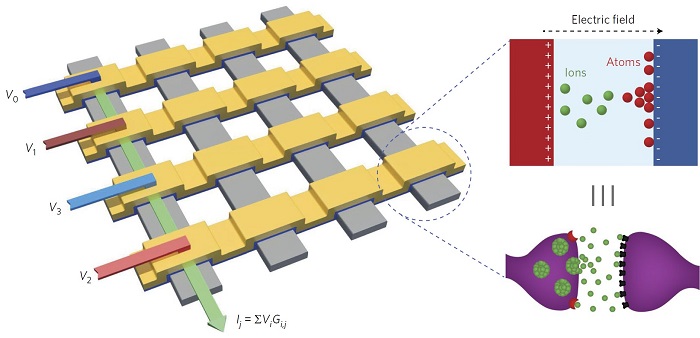
그림 2. 크로스바 어레이를 이용한 하드웨어 ANN[2].
하지만 나노소자를 활용한 하드웨어 ANN구현은 여전히 많은 기술적 난관들이 산재해 있다. 아직 나노소자의 성능이 복잡한 생물학적 역학과정 전부를 모사하기에 한계가 있다. 또한 신경망의 동작원리에 대해 모르는 부분이 너무 많다. 신경망뿐만 아니라 뇌의 전체적인 구조 및 동작 방식에 대한 이해도 필요하다. 따라서 뉴로모픽 시스템을 완성하려면 신경망과 하드웨어 ANN 간의 차이 및 연결관계를 유기적으로 이해할 수 있어야 하며, 이를 AI 기술과 접목시킬 수 있는 통찰력이 요구된다. 본고에서는 생물학적 뉴런/시냅스를 모사하기 위한 소자수준에서의 시도들, 신경망의 학습규칙 및 학습알고리즘 구현에 대한 최근 이슈를 요약하고자 한다. 뉴로모픽 시스템 연구를 이해하려면 소자, 회로, 알고리즘, 아키텍처 등 시스템 전반에 걸친 이슈들에 대한 이해가 필요하지만, 본고에서는 소자수준의 연구만을 한정하여 요약하고자 한다. 뉴로모픽 시스템의 단위 구성요소인 뉴런/시냅스 소자의 이해를 바탕으로 전체 뉴로모픽 시스템 구성에 대한 영감을 줄 수 있기를 희망한다.
Ⅱ. 본 론
1. 나노소자를 활용한 뉴런소자 및 시냅스소자
현재까지 나노소자의 흥미로운 저항변화특성을 활용하여 뉴런/시냅스의 역학과정의 모사를 시도해왔다. 전통적으로 전자공학자들은 저항을 기본 단위로 하여 저항변화특성을 분석해왔다. 또한 짧은 신호를 표현할 때 펄스라는 용어를 사용해왔다. 하지만 신경과학자들은 전통적으로 전도도를 기본단위로 신경망의 연결강도를 표현해왔으며 신경망에서 전달되는 신호를 스파이크(spike)라 지칭한다. 따라서 뉴로모픽 시스템 연구에서는 일반적으로 같은 의미를 지닌 여러 용어들이 혼용되어 사용되고 있음을 유의해야 한다.
1.1 뉴런소자
생물학적 뉴런의 주된 역할은 여러 뉴런들로부터 전달된 신호(자극)들을 시간에 대해 누적하고(integration), 이것이 특정 임계값에 도달하면 새로운 신호를 생성하여(fire) 다른 뉴런들에게 전달하는 것이다. 이러한 뉴런의 integration and fire(I&F) 역학 과정을 모사할 수 있는 여러 나노소자들이 제안되었다. 최초의 시도는 NbO2 Mott memristor 를 이용한 연구이며[10], 그 이후 상변화물질 기반[11], oxygen vacancy filament 기반[12], metal filament[13] 기반 뉴런소자들이 제안되었다. 상변화물질 기반 뉴런소자는 입력전압 신호의 누적을 상변화물질의 저항변화로서 표현한다. 저항값이 사전 설정된 임계값을 초과하면 주변회로를 통해 저항값을 초기화 해야 하기 때문에 적절한 주변회로 설계가 필수적이다[11]. Oxygen vacancy filament 기반 뉴런소자는 독특한 휘발성 저항변화(threshold switching)을 이용한다[12]. 입력 전압 신호에 의해 형성된 전도성의 oxygen vacancy filament 낮은 전압 구간에서는 유지되지 못하고 원래 상태로 돌아가려는 현상을 이용하여, 입력신호의 크기가 충분히 클 때만 filament 가 유지되어 출력신호를 생성할 수 있는 뉴런소자를 구현한다. 상변화기반 뉴런소자와는 달리 주변회로 없이도 저항값의 초기화가 가능하다는 점이 장점이 있다. metal filament 기반 뉴런소자(CBRAM 또는 diffusive memristor로도 불린다)도 동일한 휘발성 저항변화특성을 이용한다[13]. 단지 차이점은 filament를 형성하는 것이 Ag 또는 Cu 원자들이기 때문에 보다 빠른 스위칭 속도를 얻을 수 있다. 그 밖에도 트랜지스터 구조의 뉴런 소자들도 비슷한 동작 원리를 기반으로 제안되었다[14].
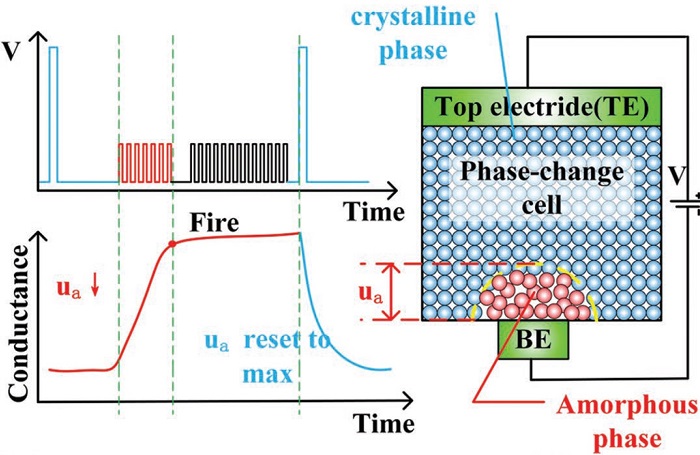
그림 3. 상변화물질 기반의 뉴런소자[15].
아직까지 뉴런소자 연구는 I&F 역학과정만을 모사하는 수준에 머물러 있다. 뉴런의 복잡한 전체 기능을 모사하기 위해서는 뉴런의 개별 부분들(소마, 축삭돌기, 수상돌기) 각각의 고유한 기능들에 대한 이해와 적절한 모사가 필요하다. 또한 뉴런소자의 안정성 및 신뢰성은 아직 전혀 검증되지 않았다. 특히 휘발성 저항변화특성의 경우 무작위성(randomness)을 지닌 메커니즘을 기반으로 하기 때문에 뉴런소자 간의 불균일성(variability) 문제가 늘 존재한다. 마지막으로 한 개의 뉴런소자는 수많은 다른 뉴런소자들과 병렬로 연결되어야 하기 때문에 높은 전류 구동 능력이 있어야 하지만 이에 대한 고민 역시 아직까지 이루어지지 못하고 있다.
1.2 시냅스소자
시냅스소자는 상대적으로 뉴런소자에 비해 더 오래전부터 연구되어왔다(그림4). 생물학적 시냅스의 주요 특징은 아날로그적으로 조절 가능한 연결강도(가중치, synaptic weight)를 가진다는 점이며, 나노소자의 저항변화특성에 쉽게 대응되어 모사될 수 있다. 다만 뉴로모픽 시스템 구성을 위해 요구되는 저항변화의 성능(저항변화 대칭성/선형성, 아날로그 저항 상태의 개수 등)은 시스템의 알고리즘이나 응용분야에 따라 달라진다[16].
시냅스소자의 동작 자체는 소자의 저항값을 조절하는 것이 전부이므로 뉴런소자에 비하면 매우 단순하다. 하지만 저항값의 정확도는 시스템 전체의 성능을 결정하며, 뉴로모픽 시스템에서 가장 많은 수를 차지하는 구성요소이기 때문에 저항변화에 필요한 에너지 양이 전체 시스템의 에너지 효율에 직접적으로 영향을 미친다. 현재 시냅스소자의 저항값을 조절하기 위해 사용되는 방식은 세 가지가 있다. 첫째, 소자의 두 전극에 정확하게 설계된 전압 펄스를 인가하여 두 펄스가 겹칠 때 저항값을 조절하는 방식이다[17]. 이 방식은 어레이에서 동시에 여러 소자의 저항값을 조절하는 것이 가능하지만 정확한 저항값 조절이 어렵다는 단점이 있다. 둘째, 펄스열(pulse train)을 인가하여 원하는 저항값에 도달할 때까지 점진적으로 저항값을 조절하는 방법이다[18]. 이 방식은 저항값을 비교적 정확하게 조절할 수 있으나, 어레이에서 한번에 한 소자만 저항값 조절이 가능하며 펄스열에 의해 에너지 소모가 많다는 단점이 있다. 셋째, 저항변화특성 중 시간 의존적 특성(relaxation dynamic)을 활용하여 생물학적 시냅스와 유사한 방식으로 입력 펄스의 타이밍에 따라 저항값을 조절하는 방식이다[13]. 이 방식은 시간 의존적 저항변화특성을 원하는 대로 조절하기 어렵다는 단점이 있다.
시냅스소자로서 활용된 저항변화특성의 메커니즘은 매우 다양하다. 그 중에서 현재로서 가장 유망한 후보는 filament 기반 저항변화특성이다. pJ 정도의 에너지 소모 만으로도 저항변화가 가능하며, 검증된 3차원 적층 가능성 및 스케일링 능력, 기존 CMOS 공정과의 뛰어난 호환성이 그 이유이다[19]. 다만 현재는 수 볼트의 동작전압이 필요하기 때문에 미래의 CMOS 기술 노드를 고려한다면 동작전압을 1 V 이하로 낮출 수 있는 기술 연구가 필요하다. 또 다른 유망한 후보로는 STT(spin transfer torque) 자성 기반의 저항변화특성이다. 이미 주요 파운드리에서 대량 생산이 가능하며, filament 기반 저항변화보다 훨씬 낮은 동작전압과 높은 내구성을 가지는 장점이 있다. 하지만 상대적으로 매우 작은 저항비(on/off ratio=2~3)를 가지며 아날로그 저항상태를 얻기가 어렵다[20]. 따라서 STT 기반 시냅스소자를 활용하려면 그에 맞는 알고리즘 및 아키텍처 설계가 뒷받침되어야 한다.
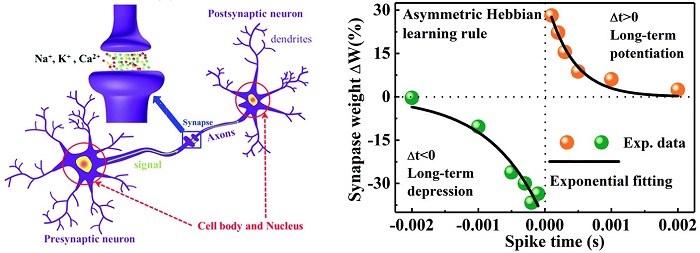
그림 4. 아날로그적 저항변화 특성을 가지는 시냅스소자[21].
1.3 요약
나노소자의 저항변화특성에 대한 연구로부터 다양한 형태의 뉴런/시냅스 소자가 보고되고 있다. 많은 성과도 있었지만 여전히 생물학적 뉴런/시냅스에 비하면 많은 차이가 존재한다. 나노소자의 저항변화특성은 대부분 하나의 특성만이 지배적으로 나타난다(예: 휘발성 또는 비휘발성). 하지만 생물학적 뉴런/시냅스는 서로 다른 유형의 이온 채널이나 다수의 복잡한 하위 구성 요소를 포함하고 있으며, 이들 모두가 전체 신경망의 기능에 기여하기 때문에 하나의 소자로 뉴런/시냅스의 복잡한 역학 과정 전부를 모사하는 것이 사실상 불가능하다. 따라서 현재처럼 단일 소자 수준의 모사에 대한 연구도 중요하지만, 앞으로는 다수의 소자 그룹을 통한 복합적인 역학과정 모사 연구가 진행되어야 할 것이다.
2. 하드웨어 ANN 학습규칙 (learning rule)
이 장에서는 학습규칙에 대해 논의한다. 학습규칙이란 신경망에서 시냅스의 연결강도를 조절하는 방식을 의미한다. 하드웨어 ANN 에서는 어떤 방식으로 시냅스소자의 저항값을 조절할지를 결정하는 규칙을 의미한다. 이를 위해 먼저 생물학적 신경망의 학습규칙에 대해 살펴보고, 이것들이 시냅스소자에서 어떻게 모사되는지를 요약하고자 한다. 사실 많은 생물학자들과 신경과학자들의 노력으로 시냅스의 연결강도를 결정짓는 다양한 학습규칙들은 실험적으로 확인이 되었으나, 본고에서는 현재의 시냅스소자로 모사가 가능한 학습규칙들로 한정하여 살펴본다.
2.1 Hebbian 학습규칙
Hebbian 학습규칙은 70 년 전에 Hebb에 의해 제안되었으며 그 이후로 대부분의 신경망 학습규칙의 기본 아이디어가 되었다[22]. Hebbian 학습규칙은 ‘양쪽 뉴런이 동시에 또 반복적으로 활성화된다면, 그 두 뉴런사이에 놓인 시냅스의 연결강도가 강화된다’ 이다. 이러한 Hebb의 통찰력 있는 가설은 다음과 같은 여러 형태의 시냅스 가소성(synaptic plasticity)의 관측 통해 실제로 확인되었다.
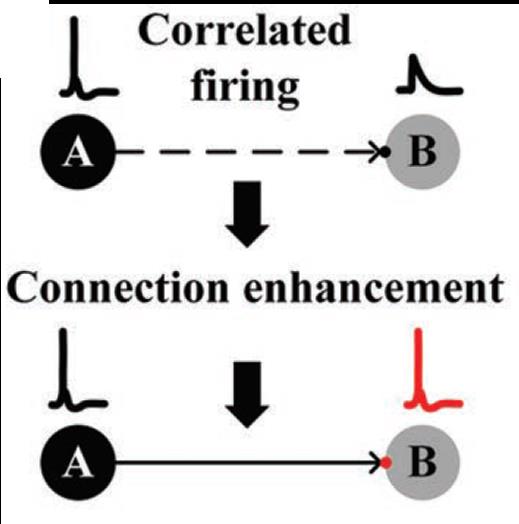
그림 5. Hebbian learning을 표현한 모식도.
2.2 Spike Rate Dependent Plasticity (SRDP)
Hebb의 규칙에 따라 시냅스의 연결강도는 양쪽 뉴런의 활성화정도에 비례하여 증가한다. 여기서 활성화정도란 뉴런의 firing 빈도(frequency)를 의미한다. 즉 SRDP는 뉴런 스파이크 빈도에 따라 시냅스의 연결강도가 변화되는 규칙을 뜻한다. 하지만 원래의 Hebb의 규칙에는 연결강도의 강화(long-term potentiation, LTP)만 있고, 억압(long-term depression, LTD)은 포함하지 않고 있다. 따라서 이후에 개선된 BCM (Bienenstock, Cooper, and Munro) 규칙에는 뉴런의 활성화정도에 따라 LTP 와 LTD 모두 설명할 수 있도록 수정되었다[23].
시냅스소자에서 SRDP 모사는 인가되는 펄스열의 주파수에 따른 저항변화 특성을 활용한다(그림6). 높은 주파수(20~100Hz)의 펄스열이 인가되면 저항값이 감소하며(LTP), 반대로 낮은 주파수(1~5Hz)의 펄스열이 인가되면 저항값이 증가하는(LTD) 독특한 저항변화특성을 활용한다. 그동안 CMOS 회로[24], 저항변화소자[25], CMOS/저항변화소자 복합체[26], perovskite 소자[27] 등에서 SRDP 가 성공적으로 모사 되었다. 하지만 SRDP가 신경망 전체의 학습알고리즘에 어떤 식으로 기여하는지는 아직 확실하지 않다.
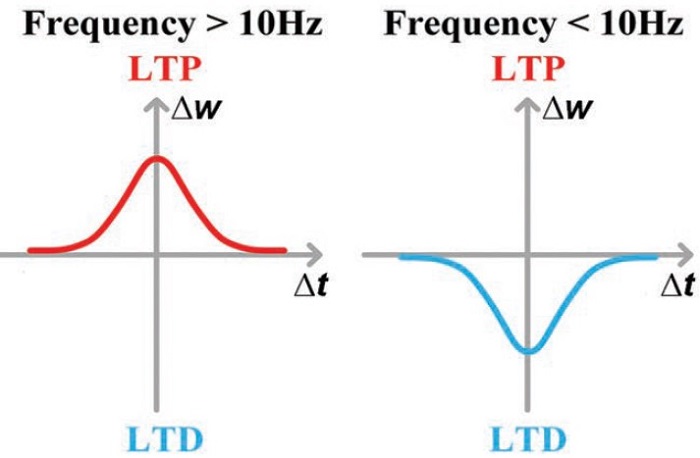
그림 6. SRDP를 표현한 모식도.
2.3 Spike Timing Dependent Plasticity (STDP)
STDP는 Hebbian 학습규칙이 약간 변형된 형태의 스파이크 기반 학습규칙으로 현재까지 가장 많이 연구된 학습규칙이다[28]. STDP 규칙에 따르면, 앞쪽 뉴런의 스파이크가 뒤쪽 뉴런의 스파이크보다 빠르게 시냅스에 작용하면 (Δt>0) 시냅스의 연결강도는 증가한다 (그림7). 반대인 경우 (Δt<0) 시냅스의 연결강도는 감소한다. 이렇게 스파이크의 정교한 타이밍에 의해 결정되는 학습규칙은 많은 연구를 통해 신경망에서 실재하는 것이 밝혀졌으며, 다수의 STDP 기반 신경망 전체의 학습알고리즘도 제안되었다[29]. 하지만 STDP 만으로 신경망 전체의 학습알고리즘을 이해하기에는 한계가 있다. 첫째, 일반적으로 학습에 필요한 시간이 수 분에서 수 시간이 필요한 반면, STDP는 수십 밀리 초 이내에 적용되는 규칙이기 때문에 거시적 시간과 미시적 시간에 큰 차이가 있다. 이는 더 긴 시간 규모에서 작동하는 미지의 학습규칙이 존재함을 의미한다. 둘째, STDP는 두 개의 스파이크 쌍을 기반으로 하는 학습 규칙으로 여러 쌍의 스파이크가 발생하는 상황에 대해서는 설명이 어렵다. 셋째, STDP 규칙은 여러 외부 요인에 의해 여러 형태로 변형이 가능하며[30], 이러한 다양성을 한번에 설명할 수 있는 통합적 규칙은 아직 제안되지 못했다. 그럼에도 불구하고 STDP는 가장 잘 알려진 학습규칙이며, 신경망의 학습알고리즘에 중요한 역할을 차지하는 것은 분명하다.
시냅스소자에서 STDP의 모사는 일반적으로 두 전극에 인가된 두 전압 펄스의 겹침(overlap)을 이용한다[31]. SRDP 모사에 독특한 저항변화특성이 필요한 것과는 달리, STDP는 거의 모든 저항변화특성에서 쉽게 모사가 가능하다. 다만 두 전압 펄스의 타이밍 차이를 폭의 차이로 변환될 수 있도록 전압 펄스의 파형을 특별하게 설계하는 것이 필요하며, 이 때문에 복잡한 주변회로를 필요로 하게 된다. 최근 이 문제점을 극복하기 위해 두 개의 메커니즘이 기여하는 저항변화특성(second-order behavior)을 활용하여 펄스의 겹침 없이도 STDP 를 모사할 수 있는 아이디어가 제안되었다[32], [33].
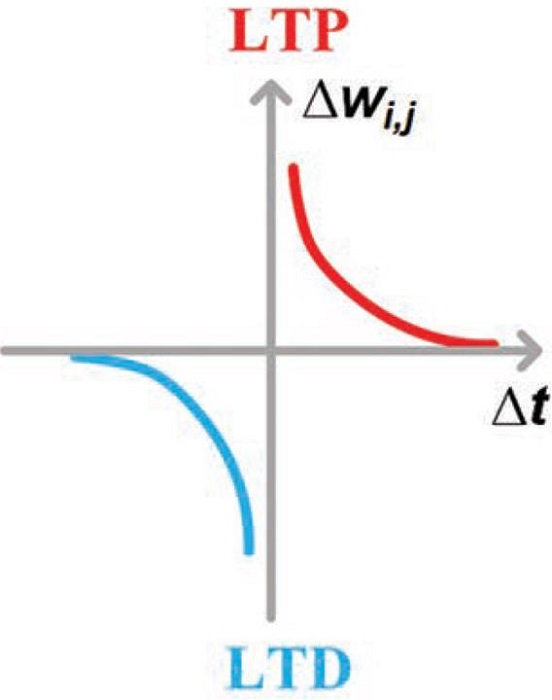
그림 7. STDP를 표현한 모식도.
2.4 요약
실제 신경망에서는 다양한 학습규칙들이 복합적으로 작용하여 신경망 전체의 학습알고리즘을 완성한다. SRDP 와 STDP 이외에도 신경과학자들에 의해 실험적으로 밝혀낸 학습규칙들은 많지만 시냅스소자로 모사할 수 있는 학습규칙은 아직까지 매우 제한적이다. 따라서 하드웨어 ANN에 적용할 악습알고리즘을 구현하기 위해서는 현재로서는 제한된 학습규칙만을 활용할 수밖에 없다는 한계가 존재한다.
3. 하드웨어 ANN에서 학습알고리즘 구현
이 장에서는 앞서 논의한 학습규칙을 하드웨어 ANN에 적용하여 다양한 형태의 학습알고리즘을 구현한 최신 결과에 대해 요약하고자 한다. 아직은 뇌의 학습알고리즘에 대해서 이해하고 있는 부분이 매우 적기 때문에, 컴퓨터공학에서 머신러닝을 위해 개발된 학습알고리즘을 하드웨어 ANN에 적용하려는 시도가 주를 이루고 있다. 이 때 발생하는 이슈들을 살펴보고자 한다.
3.1 지도/비지도 학습 (supervised/unsupervised learning)
컴퓨터공학에서 비지도학습은 레이블(label)이 없는 데이터로부터 데이터들 사이의 숨겨진 구조, 패턴, 또는 특징을 찾아내 새로 입력된 데이터를 분류할 수 있도록 하는 알고리즘이다. 이에 반해 지도학습은 레이블이 지정된 데이터를 통해 함수를 추론하고 입력(일반적으로 벡터)을 올바른 출력 값에 매핑할 수 있도록 하는 알고리즘이다. 현재까지 비지도/지도 학습에 필요한 다양한 알고리즘들이 성공적으로 개발되었다. 예를 들면, 머신러닝에서 일반적으로 지도학습을 위해 역전파(back propagation) 방식을 사용한다. 실제값과 추론값의 차이(에러)를 최소화하기 위해 뉴런층(layer)들을 역으로 거슬러서 계산되는 값을 활용하여 시냅스의 가중치를 반복적으로 재조정하는 방식이다.
주목해야 할 점은, 하드웨어 ANN에서 컴퓨터공학에서의 학습알고리즘을 구현할 때 스파이크의 생성 및 전달이 중요한 변수가 된다는 점이다. 시냅스의 가중치를 재조정하는 것이 소프트웨어적으로는 단순한 변수 값의 재조정이지만 (물론 복잡한 계산이 수반되지만), 하드웨어적으로는 스파이크를 적절하게 생성하여 특정한 시냅스소자에 인가하는 과정이기 때문이다. 2장에서 살펴보았듯이 시냅스소자로 구현이 용이한 학습규칙은 현재로서는 STDP뿐이다. 문제는 STDP를 이용하여 역전파방식을 구현하는 것이 매우 어렵다는 점이다. 몇몇 이 문제를 해결할 수 있는 방법들이 제안되었지만 역전파방식에 비해 성능이 매우 떨어지거나[34], 복잡한 디지털 타입의 주변회로를 필요로 한다[35]. 따라서 아직까지 지도학습 알고리즘을 하드웨어 ANN으로 구현하는 것은 매우 어렵다. 이러한 상황에서 조금 다른 접근으로, 지도학습 알고리즘에는 (대부분의 머신러닝 알고리즘에는) 수많은 행렬 곱셈 연산이 필요하며, 이는 기존의 컴퓨터에서 많은 양의 컴퓨팅 리소스를 필요로하는 부담이 큰 연산 중 하나이다. 하지만 크로스바 구조의 시냅스소자 어레이는 행렬 곱셈 연산을 매우 쉽게 수행할 수 있음이 알려져 있다. 따라서 시냅스소자 크로스바 어레이(dot-product engine 이라 불림)를 이용하여 지도학습(또는 머신러닝)에 필요한 행렬 곱셈 연산을 에너지 효율적으로 수행한 결과들이 최근에 보고되고 있다[17], [18], [36]. 즉, 학습알고리즘을 하드웨어 ANN으로 직접 구현하려는 시도 보다는 간접적으로 시냅스소자 어레이를 머신러닝 연산의 가속기로서 활용하려는 시도가 보다 더 활발히 이루어지고 있다.
상대적으로 하드웨어 ANN에서 비지도학습 알고리즘을 구현하는 것은 용이하다. 그 이유는 이미 이론적으로 STDP 기반의 비지도학습 알고리즘은 오랜 시간동안 연구되어왔기 때문에, 이를 실험적으로 구현한 결과들이 성공적으로 보고되고 있다[13], [37]. 하지만 고집적된 하드웨어 ANN제작이 아직 어려워 비지도학습을 통한 이미지 인식의 성능은 현재까지 겨우 4×4 픽셀을 가진 이미지만이 가능한 수준이다[13]. 성능적인 측면에서는 머신러닝과 감히 비교할 수 없는 수준이지만, 적은 전력소모만으로 학습알고리즘의 구현이 가능함에 주목해야 한다.
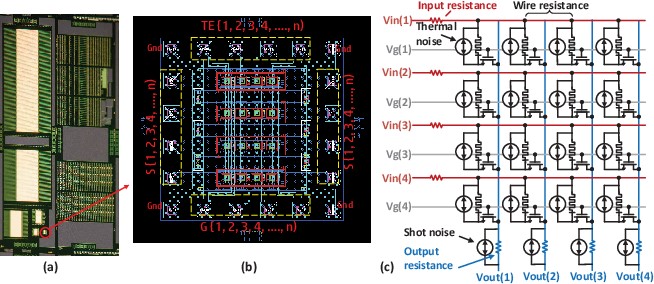
그림 8. 하드웨어 ANN 을 활용한 dot-product engine 예[38].
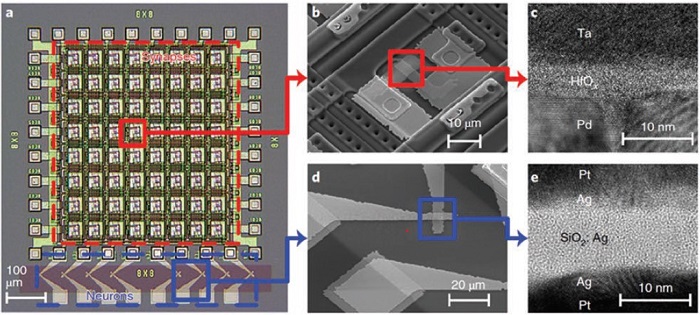
그림 9. 하드웨어 ANN 에서의 비지도학습 예[13].
3.2 강화학습 (reinforcement learning)
강화학습은 앞서 살펴본 지도/비지도 학습과는 약간 다른 방식의 학습알고리즘이다. 앞서 살펴본 알고리즘들이 데이터가 주어진 정적인 상태에서 학습을 진행하였다면, 강화학습은 주어진 환경에 대해 어떤 행동을 취하고, 이로부터 어떤 보상을 얻으면서 학습을 진행한다. 즉, 강화학습은 일종의 동적인 상태에서 데이터를 수집하는 과정까지 포함되어 있는 알고리즘이다.
강화학습의 구체적인 예는 알파고(AlphaGo)이다. 알파고의 ANN은 지도학습과 셀프게임(self-game) 기반의 강화학습을 통해 학습되었다. 특히 알파고의 업데이트 버전인 알파고 제로(AlphaGo Zero)는 오직 강화학습만을 사용하여 기존 알파고와의 100번의 게임에서 100번 모두 이기는 결과를 보여주었다[39].
지도학습의 경우와 마찬가지로, 하드웨어 ANN은 강화학습의 행렬 곱셈 연산을 돕는 보조적 역할로서 활용이 보고되었다[40]. 다만 매우 높은 정확도의 연산 결과가 필요한 강화학습 알고리즘에서 저항변화특성의 불균일성(variability) 때문에 발생하는 가중치 값의 오차가 중요한 이슈로 부각되고 있다. 이를 해결하기 위해 stochastic gradient강화학습 알고리즘을 사용하는 것을 시도하고 있다.
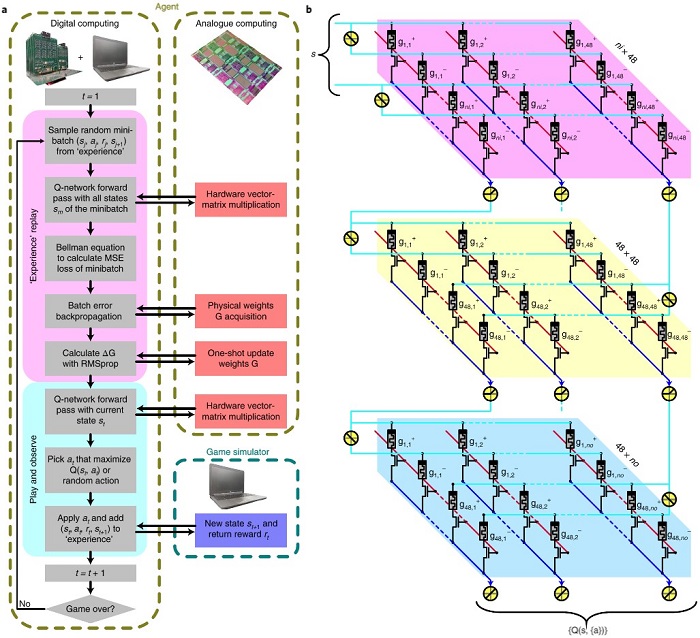
그림 10. 하드웨어 ANN 을 활용한 강화학습 예[40].
3.3 축적컴퓨팅 (reservoir computing)
축적컴퓨팅은 시간에 따라 변하는 데이터를 학습하기 위한 학습알고리즘이다. 이 알고리즘은 단기기억(short-term memory) 특성을 갖는 reservoir를 이용하여 시간에 따른 입력의 특징정보를 고차원의 공간으로 투사한다. 보다 쉽게 이야기하면 아주 복잡한 비선형적 함수특성을 가지는 reservoir를 이용해 입력신호를 높은 차원으로 매핑한다. 그런 다음 reservoir의 입출력을 담당하는 함수만 기존의 학습알고리즘을 이용해 학습시키게 된다. 축적컴퓨팅의 장점은 reservoir는 고정이고 입출력 함수만 학습시키면 되기 때문에 학습시켜야 하는 ANN이 최소화된다. 다만 reservoir 안의 네트워크 노드(뉴런)는 입력에 따라 시간적으로 변해야 하며, 결과적으로 reservoir내부 상태는 과거의 입력과 현재의 입력 모두에 의해서 결정되어야 한다. 따라서 축적컴퓨팅을 위해서는 단기기억특성을 가진 매우 독특한 특성을 가진 reservoir가 반드시 필요로 하게 된다.
축적컴퓨팅 알고리즘을 하드웨어로 구현할 때는 reservoir를 어떻게 구현할지가 관건이다. 그동안 FPGA, 실리콘 포토닉스 칩 등을 이용해 reservoir를 구현하였으며, 이를 통해 시간적 분류, 회귀, 예측이 필요한 음성인식과 같은 응용분야에 적용되었다[41]. 하지만 최근 들어 시냅스소자의 단기저항변화특성을 활용하여 reservoir를 구현하고, 이를 활용한 이미지 인식을 보여준 결과가 발표되었다[42]. 아직은 초기단계의 시도이며 앞으로 많은 부분에서의 연구가 추가적으로 필요하다.
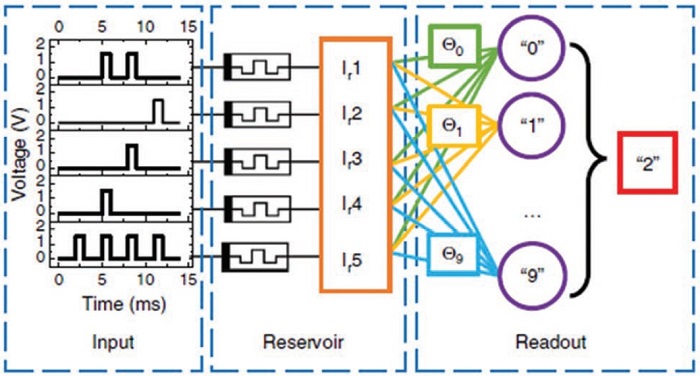
그림 11. 단기저항변화특성을 활용한 축적컴퓨팅 예[42].
3.4 one-shot 또는 few-shot 학습
One-shot 학습은 현재 머신러닝 연구에서 가장 최신의 연구 주제이다. 앞에서도 언급하였듯이 최근의 AI 발전에는 활용가능한 빅데이터의 증가가 크게 기여하였다. 즉 기존의 머신러닝에는 ANN학습을 위한 많은 양의 데이터를 필요로 한다. 하지만 우리 인간만 보더라도 학습을 위해 많은 양의 데이터를 필요로 하지 않는다. 어린 나이의 아이라도 단 몇 번의 사과 사진을 보는 것만으로도 충분히 사과를 구별해낼 수 있다. 이것이 가능한 이유는 뇌의 연산능력이 컴퓨터보다 뛰어나기 때문이 아니라, 기존에 배운 제한된 정보로부터 새로운 객체에 대한 클래스(class)를 합성해낼 수 능력이 있기 때문이다. One-shot 학습은 사람과 같은 효율적인 학습을 목표로 하는 알고리즘이다. 이를 위해 현재 두가지 방법이 시도되고 있다. 첫째, 지도학습을 기반으로 하여 제한된 데이터를 직접 학습하는 방법으로, 이를 위해서는 아주 명시적인 선험적 모델 (priori model)이 필요하다. 둘째, 전송학습 (transfer leaning)이라 불리는 방법으로, 작은 데이터로부터 얻어진 학습 결과를 곧바로 ANN에 전송하는 방법이다[43].
one-shot 학습에 대한 연구는 아직 기초 수준이며, 이를 도울 수 있는 하드웨어 역시 기초수준에서 제안되고 있다. 네 개의 수직 적층된 저항변화메모리 어레이를 활용하여 곱셈, 덧셈, 치환 연산을 보조할 수 있는 결과나[44], FinFET 메모리의 빠른 수렴성을 이용한 빠른 하드웨어 ANN 학습 아키텍처 등이 최근에 제시되었다[45].
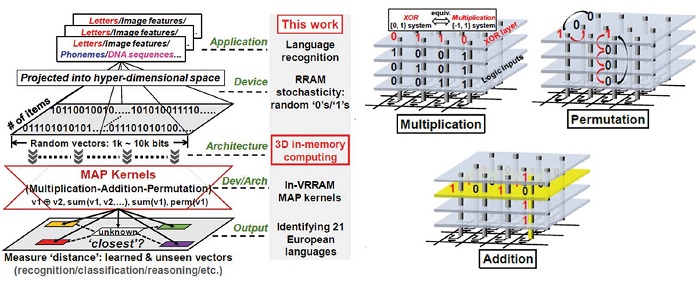
그림 12. One-shot 학습을 위한 하드웨어 아키텍처[44].
Ⅲ. 결 론
나노소자를 활용한 최근의 성공적인 뉴런/시냅스 모사연구는 상당히 많은 연구자들의 관심을 불러 일으켰다. 또한 하드웨어 ANN을 활용한 성공적인 응용 결과도 뉴로모픽 시스템에 대한 기대감을 더욱더 높이고 있다. 하지만 자칫 잘못하면 뉴로모픽 시스템 연구에 대해 잘못된 오해를 가지기 쉽다. 만약 우리가 지금 이 시점에서 뇌에 대해 모든 것을 알고 있다면, 뉴로모픽 시스템을 구현하는 것은 매우 쉬운 일일 것이다. 달리 말하면 뇌에 대해 모든 것을 알기 전까지는 뇌와 모든 것이 동일한 뉴로모픽 시스템을 구현하는 것은 불가능함을 의미한다. 명심해야 할 점은 뉴로모픽 시스템 연구의 목적은 뇌의 기능적/구조적 특징을 ‘선택적으로 모사’하여 기존 디지털 컴퓨팅 시스템보다 더 에너지 효율적인 장점을 가지는 컴퓨팅 시스템을 만들려는 것이지, 뇌를 ‘그대로 복사’한 인공전자두뇌를 만들려는 것은 아니다. 따라서 올바른 뉴로모픽 시스템 연구를 위해서는 먼저 하드웨어 구현 능력을 고려하여 모사의 범위를 적절하게 설정하고, 이를 통해 응용분야를 명확하게 정의하는 것이 매우 중요하다. 이러한 과정없이 맹목적으로 뉴런/시냅스를 모사하는 것에만 초점을 맞추면 뉴로모픽 시스템의 완성은 아주 먼 미래에나 가능할지 모른다.
뉴로모픽 시스템은 많은 경쟁자들이 존재한다. 뉴로모픽 시스템은 기존 디지털 컴퓨팅 시스템의 한계에 대한 대안책으로 시작된 연구이다. 하지만 기존 디지털 컴퓨팅 시스템 역시 다양한 나노소자들의 개발을 통해 지속적인 성능 개선의 가능성을 여전히 열어 두고 있다. 이와 더불어 one-shot 학습과 같이 보다 더 효율적인 머신러닝 알고리즘 개발을 통한 소프트웨어적 성능 개선도 꾸준히 시도되고 있다. 이러한 상황에서 양자컴퓨팅과 같은 새로운 컴퓨팅 시스템은 이미 양산 단계에 진입하는 중이다. 따라서 앞으로의 뉴로모픽 시스템 연구는 뉴로모픽 시스템이 반드시 필요한 응용분야의 제시와 이와 동반된 충분한 실현가능성을 보여주어야 할 것이다.
뉴로모픽 시스템 연구가 그동안 많은 연구자들의 관심을 끌 수 있는 이유는 모두가 궁금해하는 뇌라는 미지의 영역을 리버스 엔지니어링(reverse engineering)하는 성격을 가진 연구이기 때문일 것이다. 가까운 미래에 뇌를 닮은 뉴로모픽 시스템을 통해 한단계 진화된 AI기술을 일상생활에서 접할 수 있기를 진심으로 기대해 본다.
참 고 문 헌
[1] A. M. Turing, “Computing machinery and intelligence,” in Machine Intelligence: Perspectives on the Computational Model, Taylor and Francis, 2012, pp. 1–28.
[2] M. A. Zidan, J. P. Strachan, and W. D. Lu, “The future of electronics based on memristive systems,” Nat. Electron., vol. 1, no. 1, pp. 22–29, Jan. 2018.
[3] T. Gokmen and Y. Vlasov, “Acceleration of deep neural network training with resistive cross-point devices: Design considerations,” Front. Neurosci., vol. 10, no. JUL, 2016.
[4] M. Minsky, “Theory of neural-analog reinforcement systems and its application to the brain-model problem.,” Princeton University, 1954.
[5] C. Mead, “Neuromorphic Electronic Systems,” Proc. IEEE, vol. 78, no. 10, pp. 1629–1636, 1990.
[6] P. A. Merolla et al., “A million spiking-neuron integrated circuit with a scalable communication network and interface,” Science (80-. )., vol. 345, no. 6197, pp. 668–673, 2014.
[7] M. Davies et al., “Loihi: A Neuromorphic Manycore Processor with On-Chip Learning,” IEEE Micro, vol. 38, no. 1, pp. 82–99, Jan. 2018.
[8] G. Indiveri et al., “Neuromorphic Silicon Neuron Circuits,” Front. Neurosci., vol. 5, 2011.
[9] Q. Xia and J. J. Yang, “Memristive crossbar arrays for brain-inspired computing,” Nature Materials, vol. 18, no. 4. Nature Publishing Group, pp. 309–323, 01-Apr-2019.
[10] M. D. Pickett, G. Medeiros-Ribeiro, and R. S. Williams, “A scalable neuristor built with Mott memristors,” Nat. Mater., vol. 12, no. 2, pp. 114–117, 2013.
[11] H. Lim et al., “Relaxation oscillator-realized artificial electronic neurons, their responses, and noise,” Nanoscale, vol. 8, no. 18, pp. 9629–9640, May 2016.
[12] A. Mehonic and A. J. Kenyon, “Emulating the Electrical Activity of the Neuron Using a Silicon Oxide RRAM Cell,” Front. Neurosci., vol. 10, Feb. 2016.
[13] Z. Wang et al., “Fully memristive neural networks for pattern classification with unsupervised learning,” Nat. Electron., vol. 1, no. 2, pp. 137–145, Feb. 2018.
[14] H. Mulaosmanovic et al., “Mimicking biological neurons with a nanoscale ferroelectric transistor,” Nanoscale, vol. 10, no. 46, pp. 21755–21763, Dec. 2018.
[15] T. Tuma et al., “Stochastic phase-change neurons,” Nat. Nanotechnol., vol. 11, no. 8, pp. 693–699, Aug. 2016.
[16] D. Kuzum, S. Yu, and H.-S. Philip Wong, “Synaptic electronics: materials, devices and applications,” Nanotechnology, vol. 24, no. 38, p. 382001, 2013.
[17] M. Prezioso et al., “Training and operation of an integrated neuromorphic network based on metal-oxide memristors,” Nature, vol. 521, pp. 61–64, 2015.
[18] P. Yao et al., “Face classification using electronic synapses.,” Nat. Commun., vol. 8, p. 15199, May 2017.
[19] Q. Luo et al., “8-Layers 3D vertical RRAM with excellent scalability towards storage class memory applications,” in Technical Digest - International Electron Devices Meeting, IEDM, 2018, pp. 2.7.1-2.7.4.
[20] O. Golonzka et al., “MRAM as Embedded Non-Volatile Memory Solution for 22FFL FinFET Technology,” in Technical Digest - International Electron Devices Meeting, IEDM, 2019, vol. 2018-December, pp. 18.1.1-18.1.4.
[21] J. Zhao et al., “An electronic synapse memristor device with conductance linearity using quantized conduction for neuroinspired computing,” J. Mater. Chem. C, vol. 7, no. 5, pp. 1298–1306, 2019.
[22] G. Bi and M. Poo, “Synaptic Modification by Correlated Activity: Hebb’s Postulate Revisited,” Annu. Rev. Neurosci., vol. 24, no. 1, pp. 139–166, Mar. 2001.
[23] C. C. Law and L. N. Cooper, “Formation of receptive fields in realistic visual environments according to the Bienenstock, Cooper, and Munro (BCM) theory,” Proc. Natl. Acad. Sci. U. S. A., vol. 91, no. 16, pp. 7797–7801, Aug. 1994.
[24] G. Rachmuth, H. Z. Shouval, M. F. Bear, and C. S. Poon, “A biophysically-based neuromorphic model of spike rate- and timing-dependent plasticity,” Proc. Natl. Acad. Sci. U. S. A., vol. 108, no. 49, Dec. 2011.
[25] J. Yin et al., “Adaptive Crystallite Kinetics in Homogenous Bilayer Oxide Memristor for Emulating Diverse Synaptic Plasticity,” Adv. Funct. Mater., vol. 28, no. 19, p. 1706927, May 2018.
[26] V. Milo et al., “Demonstration of hybrid CMOS/RRAM neural networks with spike time/rate-dependent plasticity,” in Technical Digest - International Electron Devices Meeting, IEDM, 2017, pp. 16.8.1-16.8.4.
[27] Z. Xiao and J. Huang, “Energy-Efficient Hybrid Perovskite Memristors and Synaptic Devices,” Adv. Electron. Mater., vol. 2, no. 7, p. 1600100, Jul. 2016.
[28] G. Q. Bi and M. M. Poo, “Synaptic modifications in cultured hippocampal neurons: dependence on spike timing, synaptic strength, and postsynaptic cell type.,” J. Neurosci., vol. 18, no. 24, pp. 10464–10472, Dec. 1998.
[29] T. Serrano-Gotarredona et al., “STDP and STDP variations with memristors for spiking neuromorphic learning systems,” Front. Neurosci., vol. 7, no. 7 FEB, p. 2, 2013.
[30] V. Pawlak, J. R. Wickens, A. Kirkwood, and J. N. D. Kerr, “Timing is not everything: Neuromodulation opens the STDP gate,” Frontiers in Synaptic Neuroscience, no. OCT. 2010.
[31] S. H. Jo et al., “Nanoscale memristor device as synapse in neuromorphic systems,” Nano Lett., vol. 10, no. 4, pp. 1297–1301, 2010.
[32] Z. Wang et al., “Memristors with diffusive dynamics as synaptic emulators for neuromorphic computing,” Nat. Mater., vol. 16, no. 1, pp. 101–108, Jan. 2017.
[33] C. Du et al., “Biorealistic Implementation of Synaptic Functions with Oxide Memristors through Internal Ionic Dynamics,” Adv. Funct. Mater., vol. 25, no. 27, pp. 4290–4299, Jul. 2015.
[34] R. V. Florian, “The chronotron: A neuron that learns to fire temporally precise spike patterns,” PLoS One, vol. 7, no. 8, Aug. 2012.
[35] W. Wang et al., “Learning of spatiotemporal patterns in a spiking neural network with resistive switching synapses,” Sci. Adv., vol. 4, no. 9, Sep. 2018.
[36] S. Ambrogio et al., “Equivalent-accuracy accelerated neural-network training using analogue memory,” Nature, vol. 558, no. 7708, pp. 60–67, Jun. 2018.
[37] S. Choi et al., “Experimental Demonstration of Feature Extraction and Dimensionality Reduction Using Memristor Networks,” Nano Lett., vol. 17, no. 5, pp. 3113–3118, May 2017.
[38] M. Hu et al., “Dot-product engine for neuromorphic computing: Programming 1T1M crossbar to accelerate matrix-vector multiplication,” in Proceedings of the 53rd Annual Design Automation Conference on - DAC ’16, 2016, pp. 1–6.
[39] D. Silver et al., “Mastering the game of Go without human knowledge,” Nature, vol. 550, no. 7676, pp. 354–359, Oct. 2017.
[40] Z. Wang et al., “Reinforcement learning with analogue memristor arrays,” Nat. Electron., vol. 2, no. 3, pp. 115–124, Mar. 2019.
[41] K. Vandoorne et al., “Experimental demonstration of reservoir computing on a silicon photonics chip,” Nat. Commun., vol. 5, Mar. 2014.
[42] C. Du et al., “Reservoir computing using dynamic memristors for temporal information processing,” Nat. Commun., vol. 8, no. 1, p. 2204, Dec. 2017.
[43] “One-shot Learning with Memory-Augmented Neural Networks,” arXiv:1605.06065, 2016. .
[44] H. Li et al., “Hyperdimensional computing with 3D VRRAM in-memory kernels: Device-architecture co-design for energy-efficient, error-resilient language recognition,” in Technical Digest - International Electron Devices Meeting, IEDM, 2017, pp. 16.1.1-16.1.4.
[45] J. L. Kuo et al., “An energy efficient FinFET-based Field Programmable Synapse Array (FPSA) feasible for one-shot learning on EDGE AI,” in Digest of Technical Papers - Symposium on VLSI Technology, 2018, vol. 2018-June, pp. 29–30.